
기록
RNN 과 LSTM 정리 본문
RNN 은 출력이 입력으로 활용되는 Recurrent 구조를 가지고 있다.
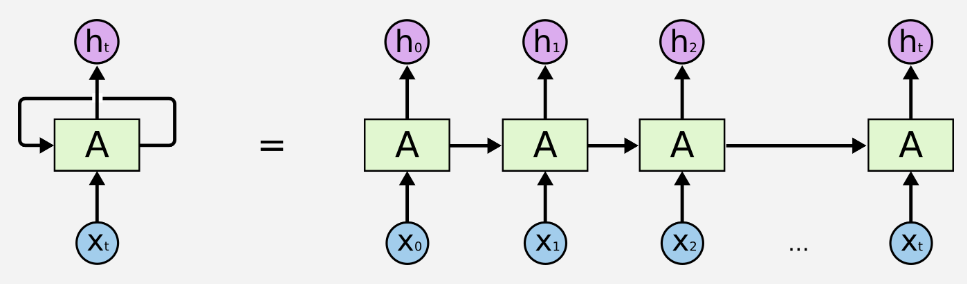
아래는 이러한 시퀀스 구조를 쫙 펼쳤을때의 그림을 나타낸다.

왼쪽그림은 오른쪽에서 cell들의 반복되는 구조를 의미한다.
입력으로 들어오는 시퀀스 데이터를 time step에 따라 처리한다.
예를들어서, 입력 데이터가 "hello"일때
이를 원-핫 인코딩 처리를 하여 벡터화 한 경우
h = [1, 0, 0, 0]
e = [0, 1, 0, 0]
l = [0, 0, 1, 0]
o = [0, 0, 0, 1]
로 표현할 수 있다.
이 경우, h, e, l, o 4개의 문자를 사용하였기에 차원의 수는 4이다.
순차적으로, 입력 데이터 X_0, X_1, X_2, ... 에는 "hello"를 원-핫 인코딩한 데이터가 들어간다.
h = X_0 = [1,0,0,0]
e = X_1 = [0,1,0,0]
l = X_2 = [0,0,1,0]
l = X_3 = [0,0,1,0]
o = X_4 = [0,0,0,1]
"hello" 총 sequence_length 는 5이기에 5개의 cell만큼 반복된다.
h_0, h_1, h_2, h_3, h_4 까지 rnn이 반복된다.
여기에 rnn의 layer를 깊게 쌓는다면
처음과 같이 옆으로 반복되어 가는것이 아닌 h_0, h_1, h_2, ... h_t 가 두번째 layer의 input 데이터가 된다!
옆으로 반복되어 학습하는 것은 하나의 rnn layer의 cell을 의미하고 이 cell의 개수는 sequence length가 된다.
결국 학습하는 형태는 몇개의 단어를 학습할지(batch_size)와 cell의 개수를 의미하는 sequence_length와 입력 데이터의 차원이다.
또한 rnn에서 relu를 사용하지 않고 sigmoid, tanh를 사용하는 이유가 있다.
relu가 성능적인 측면에서 gradient vanishing 문제를 해결할 수 있는 장점이 있지만, rnn의 특징은 같은 레이어를 반복한다는 성질을 가지고 있다. 또한, relu는 양수의 입력값인 경우 그 값을 그대로 사용하기에 1보다 큰 경우가 들어오면 값이 너무 커질 수 있다.
그래서 rnn에서는 relu를 사용하지 않고 sigmoid나 tanh를 사용한다.
sigmoid 와 tanh는 -1~1의 값을 출력하기 때문이다.
여기서 sigmoid는 미분시 기울기가 0~0.25 이고 tanh는 기울기가 0~1 이기에 tanh가 gradient vanishing 문제에서 더 좋은 성능을 보인다. sigmoid가 gradient vanishing 문제가 발생할 확률이 더 높다!
하지만, 이러한 rnn의 단점은 관련 정보와 그 정보를 사용하는 특정 지점 사이의 거리가 멀 경우 backpropagation시 학습 능력이 떨어진다. 이 문제를 극복하기 위해 LSTM이 제안되었다.

LSTM은 RNN이 가지고 있는 과거의 정보를 특정 시점에서도 오래 기억하기 위해서 3개의 게이트를 사용한다.
1. input gate : 현재 정보를 얼마나 기억할지에 대한 게이트, h_t-1과 x_t를 받아 시그모이드와 하이퍼볼릭탄젠트를 취한다. 시그모이드의 출력은 0~1의 값이기에 정보의 정도인(강도)를 나타내고 하이퍼볼릭탄젠트의 출력은 -1~1이기에 정보의 방향을 나타낸다.
2. forget gate : 과거 정보를 얼마나 기억할지에 대한 게이트, h_t-1과 x_t를 받아 시그모이드를 취한 값이다. 시그모이드의 출력 범위가 0~1이기에 값이 0이면 이전 상태의 정보는 잊는다고 판단하고 1이면 이전 상태의 정보를 온전히 기억하게 한다.
3. output gate : 출력 게이트
'딥러닝' 카테고리의 다른 글
| 역전파 - BackPropagation (0) | 2021.11.22 |
|---|---|
| 딥러닝(Deep Learning) 용어 - 배치 사이즈(Batch Size), 이터레이션(Iteration), 에포크(Epoch) (0) | 2021.07.21 |
| 딥러닝(deep learning) 용어 - 파라미터와 하이퍼파라미터 (0) | 2021.07.21 |
| 데이터 라벨링 (0) | 2021.06.19 |
| xml 파일 데이터를 활용하여 Image에 box 그리기 (0) | 2021.06.16 |
